Benchmarking DuckDB, BigQuery, and Athena on 20GB of Parquet Data
We benchmarked DuckDB, BigQuery, and Athena on 20GB of Parquet data. DuckDB Local was 3-10x faster. Athena scanned 4x less data than BigQuery. Full methodology and raw data included.


We ran a mix of analytical queries across four platforms to see how they compare on real-world data. This post shares our findings.
Dataset: ~20GB of financial time-series data in Parquet (ZSTD compressed)
The Platforms
| Platform | Configuration | Storage |
|---|---|---|
| DuckDB (local) | 1-32 threads, 2-64GB RAM | Local SSD |
| DuckDB + R2 | 1-32 threads, 2-64GB RAM | Cloudflare R2 |
| BigQuery | On-demand serverless | Google Cloud |
| Athena | On-demand serverless | S3 Parquet |
Hardware (DuckDB tests):
- CPU: AMD EPYC 9224 24-Core (48 threads)
- RAM: 256GB DDR
- Disk: Samsung 870 EVO 1TB (SATA SSD)
- Network: 1 Gbps
- Location: Lauterbourg, FR
DuckDB configurations tested:
- Minimal: 1 thread, 2GB RAM, 5GB temp (disk spill)
- Small: 4 threads, 8GB RAM, 10GB temp (disk spill)
- Medium: 8 threads, 16GB RAM, 20GB temp (disk spill)
- Large: 16 threads, 32GB RAM, 50GB temp (disk spill)
- XL: 32 threads, 64GB RAM, 100GB temp (disk spill)
The goal: determine which platform gives the best latency, cost, and overall experience for analytical workloads on Parquet data.
Overall Results
| Platform | Warm Median | Avg Cost/Query | Data Scanned |
|---|---|---|---|
| DuckDB Local (M) | 881 ms | - | - |
| DuckDB Local (XL) | 284 ms | - | - |
| DuckDB + R2 (M) | 1,099 ms | - | - |
| DuckDB + R2 (XL) | 496 ms | - | - |
| BigQuery | 2,775 ms | $0.0282 | 1,140 GB |
| Athena | 4,211 ms | $0.0064 | 277 GB |
M = Medium (8 threads, 16GB RAM) | XL = 32 threads, 64GB RAM
Key results:
- DuckDB on local storage is 3-10x faster than cloud platforms depending on config
- BigQuery scans 4x more data than Athena for the same queries
- DuckDB + R2 has good warm performance but significant cold start overhead
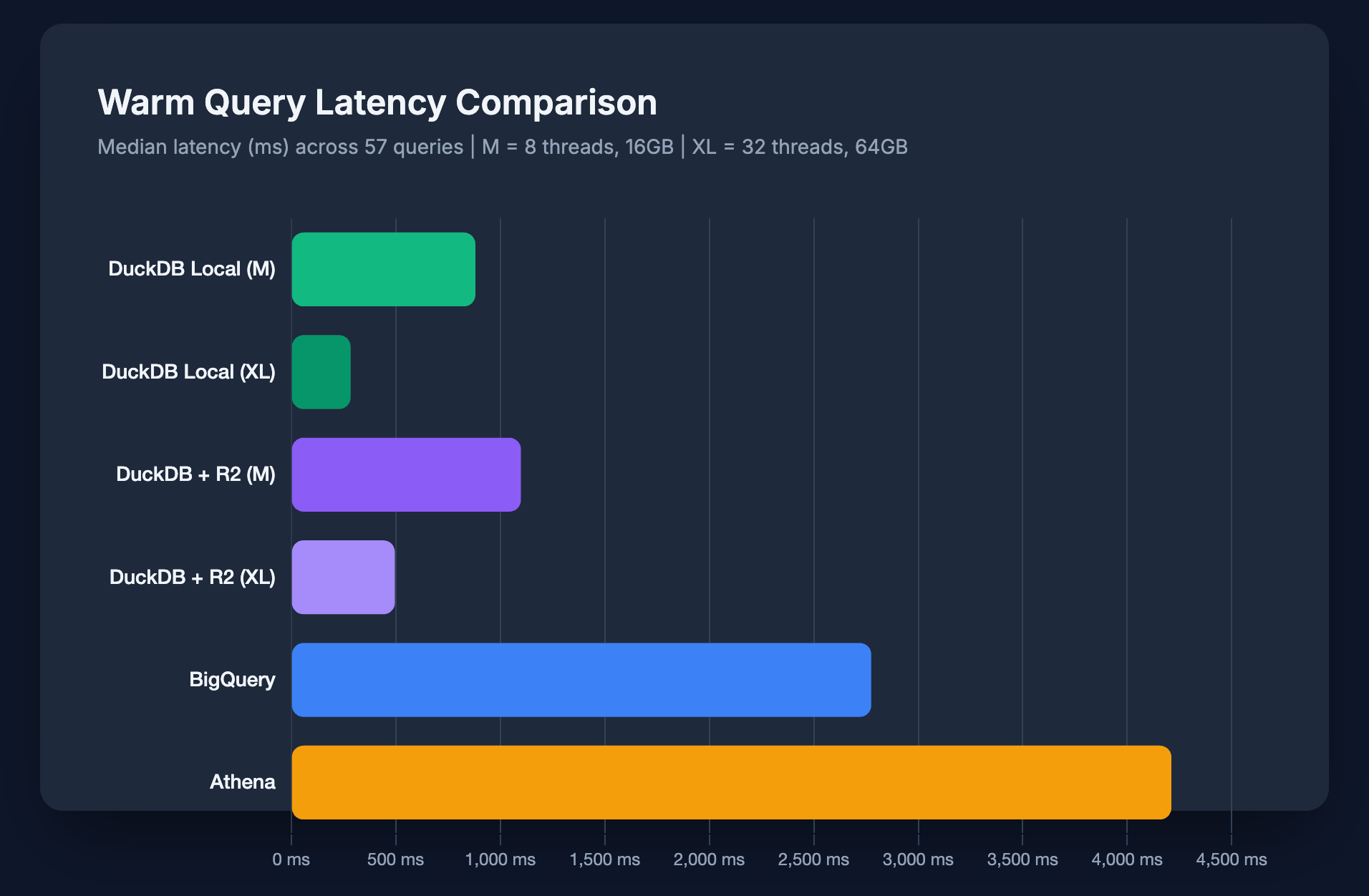
Why Is DuckDB So Fast?
DuckDB's vectorized execution engine processes data in batches, making efficient use of CPU caches. Combined with local SSD storage (no network latency), it consistently delivered sub-second query times.
Even with the medium config (8 threads, 16GB), DuckDB Local achieved 881ms median across 57 queries. With the XL config (32 threads, 64GB), that dropped to 284ms.
For comparison:
- BigQuery: 2,775ms median (3-10x slower than DuckDB)
- Athena: 4,211ms median (~5-15x slower than DuckDB)
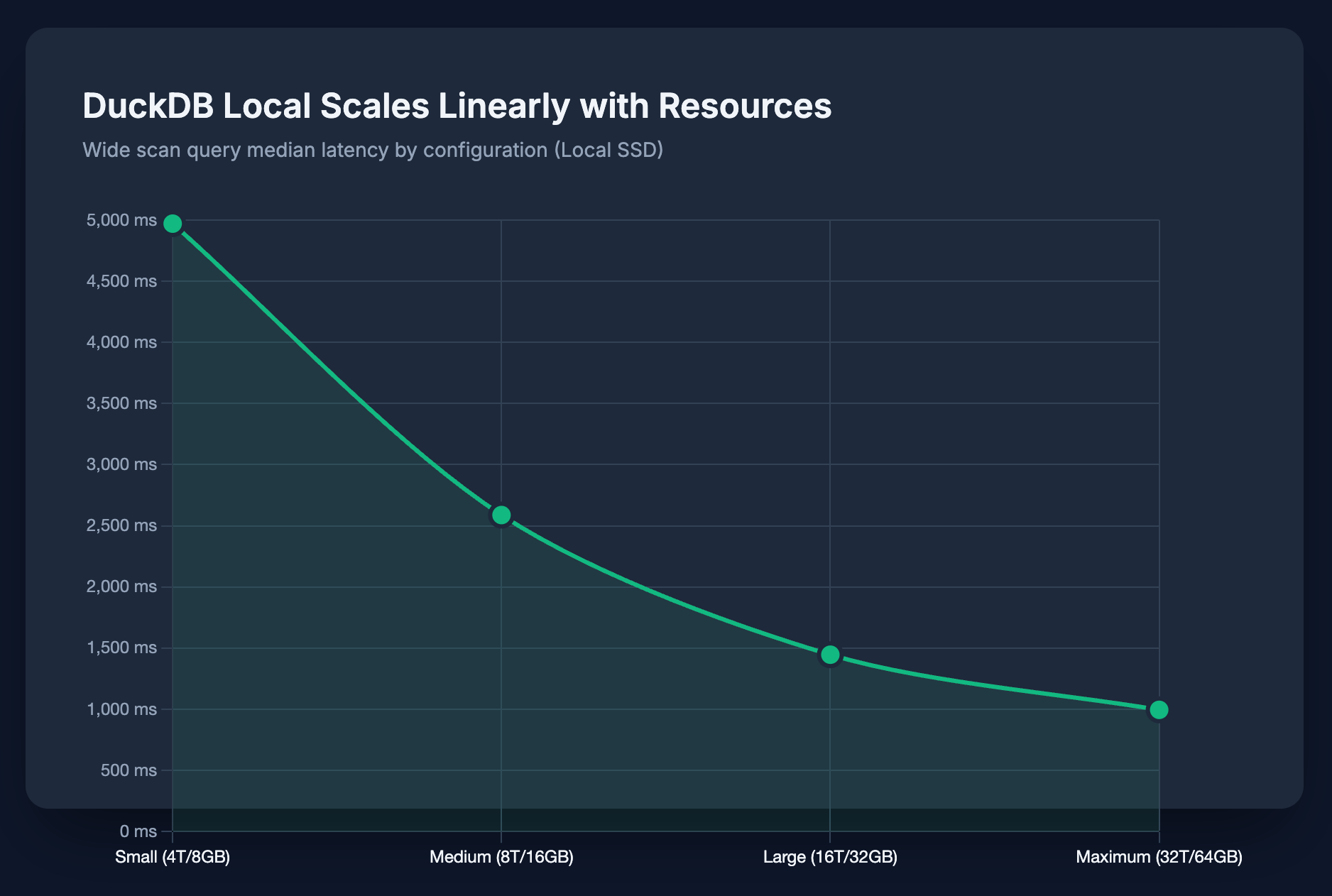
DuckDB Scales Well with Resources
Different DuckDB configurations were tested to measure scaling efficiency:
| Config | Threads | RAM | Wide Scan Median |
|---|---|---|---|
| Small | 4 | 8GB | 4,971 ms |
| Medium | 8 | 16GB | 2,588 ms |
| Large | 16 | 32GB | 1,446 ms |
| XL | 32 | 64GB | 995 ms |
Doubling resources roughly halves latency. Going from 4 threads to 32 threads (8x) improved performance by 5x. This predictable scaling makes capacity planning straightforward.
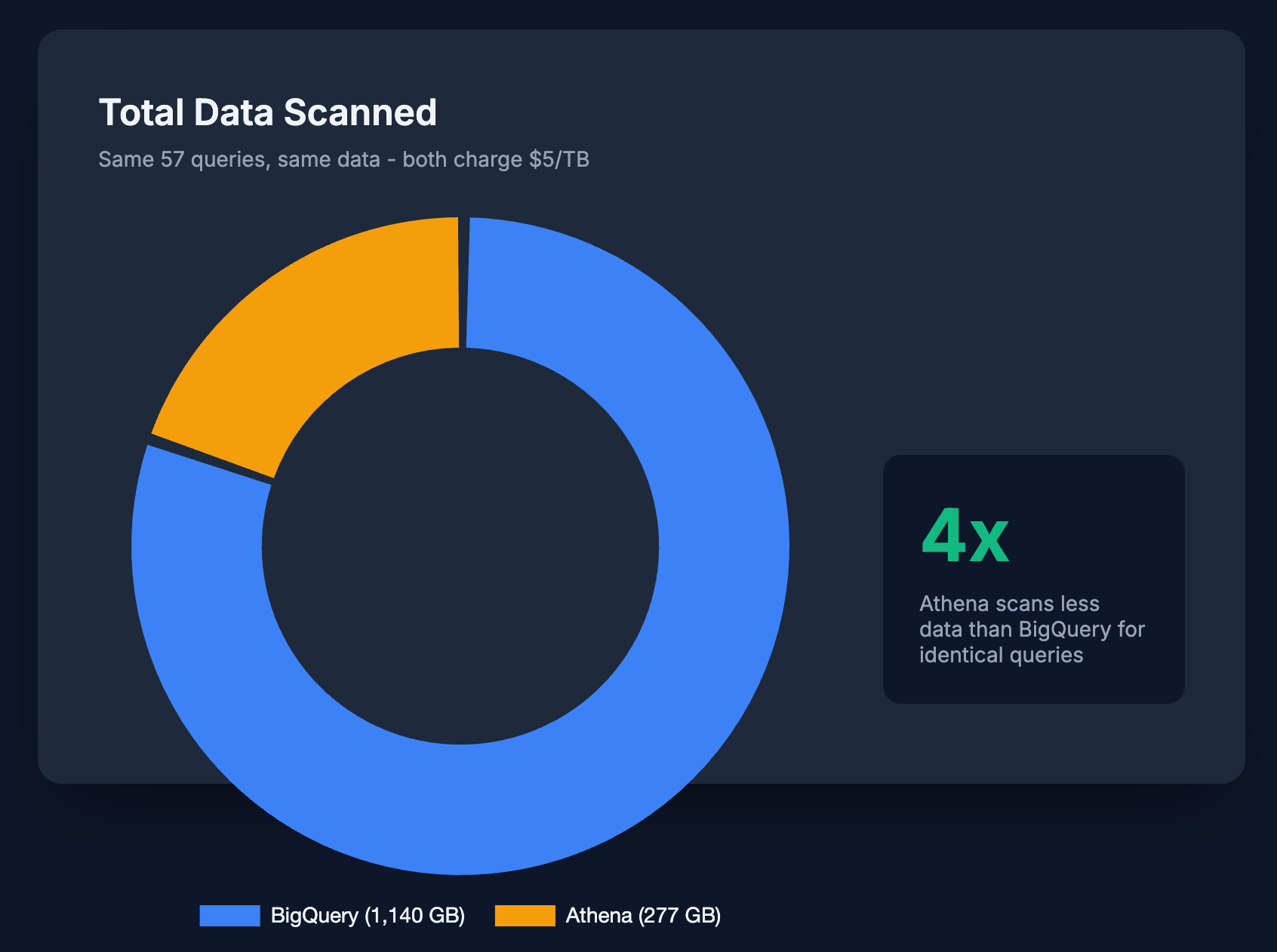
Why Does Athena Scan Less Data?
Both Athena and BigQuery charge $5/TB scanned, but:
- BigQuery scanned 1,140 GB total
- Athena scanned 277 GB total
That's a 4x difference for the same queries on the same data.
What's happening? Athena reads Parquet files directly and uses several optimizations:
- Column pruning: Only reads columns referenced in the query
- Predicate pushdown: Applies WHERE filters at the storage layer
- Row group statistics: Uses min/max values to skip entire row groups
BigQuery reports higher bytes scanned, likely due to differences in how external tables are processed and how bytes are reported (BigQuery rounds up to 10MB minimum per table scanned).
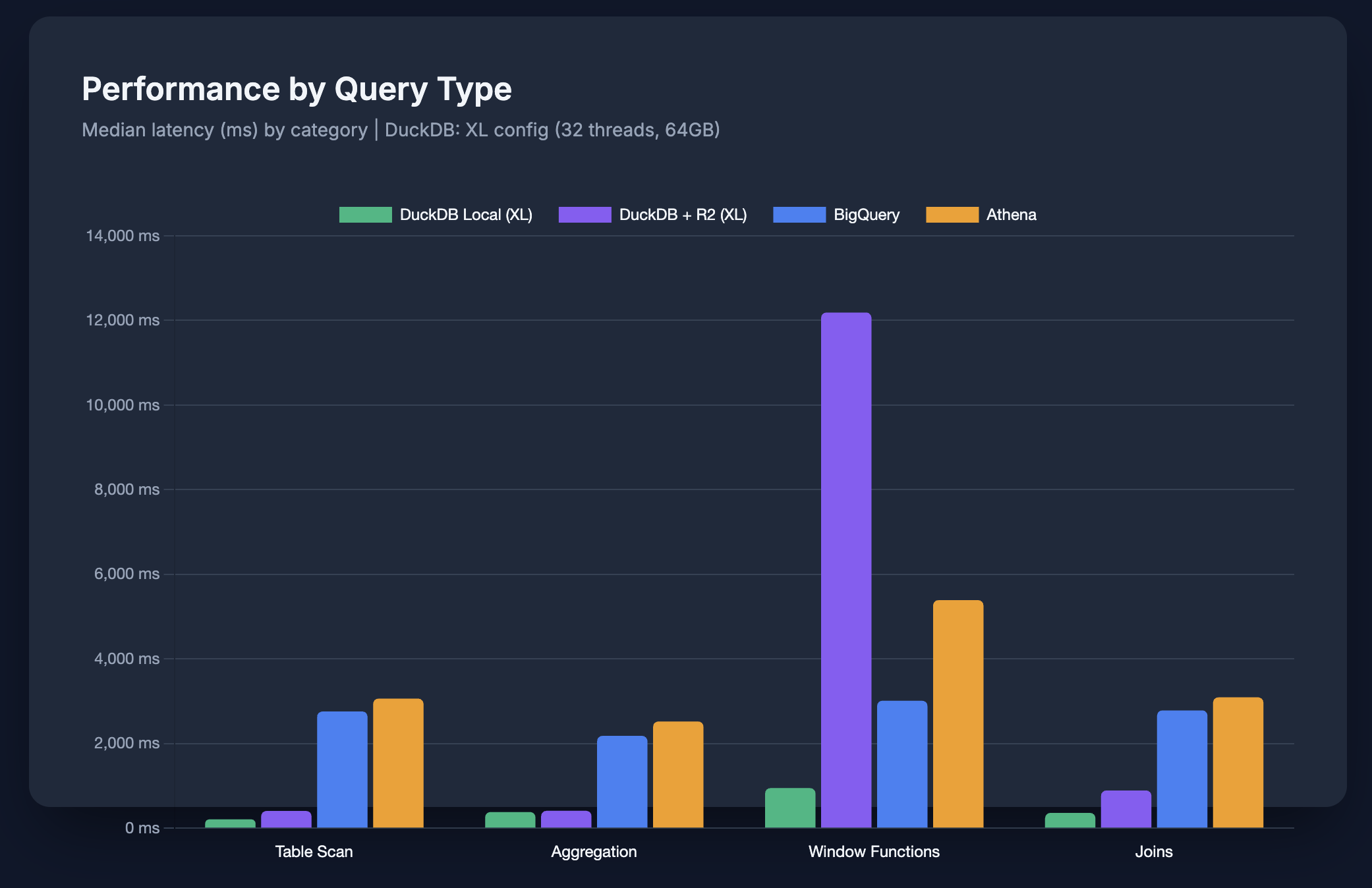
Performance by Query Type
We grouped queries into categories (DuckDB using XL config):
| Category | DuckDB Local (XL) | DuckDB + R2 (XL) | BigQuery | Athena |
|---|---|---|---|---|
| Table Scan | 208 ms | 407 ms | 2,759 ms | 3,062 ms |
| Aggregation | 382 ms | 411 ms | 2,182 ms | 2,523 ms |
| Window Functions | 947 ms | 12,187 ms | 3,013 ms | 5,389 ms |
| Joins | 361 ms | 892 ms | 2,784 ms | 3,093 ms |
| Wide Scans | 995 ms | 1,850 ms* | 3,588 ms | 6,006 ms |
*R2 wide scans: Large config (16T/32GB). XL config not tested for wide scans.
Observations:
- DuckDB Local is 5-10x faster across most categories
- Window functions hurt DuckDB + R2 badly (requires multiple passes over remote data)
- Wide scans (
SELECT *) are slow everywhere, but DuckDB still leads
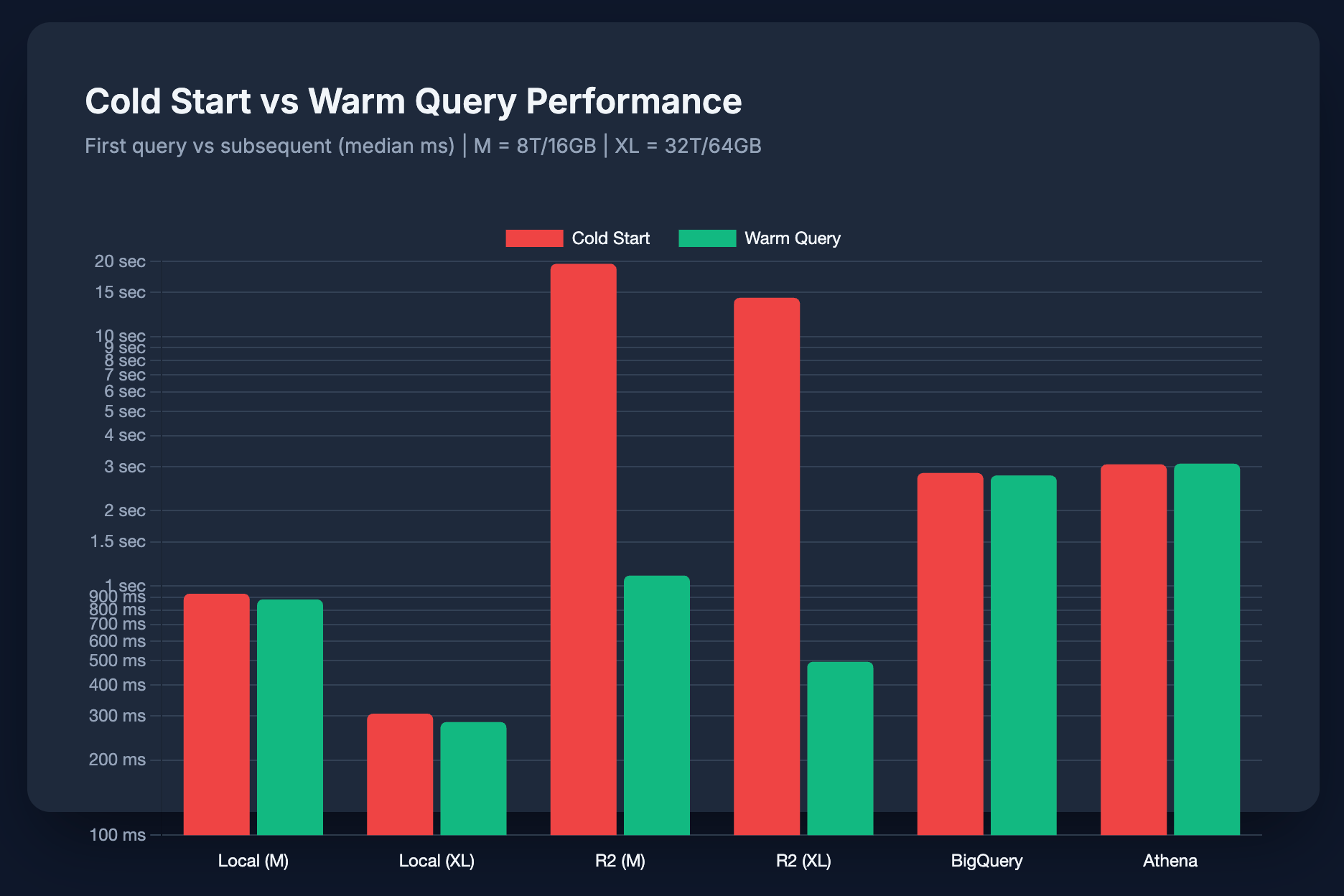
Cold Start Analysis
Cold starts are often overlooked but can dominate user experience for sporadic workloads.
| Platform | Cold Start | Warm | Overhead |
|---|---|---|---|
| DuckDB Local (M) | 929 ms | 881 ms | ~5% |
| DuckDB Local (XL) | 307 ms | 284 ms | ~8% |
| DuckDB + R2 (M) | 19.5 sec | 1,099 ms | ~1,679% |
| DuckDB + R2 (XL) | 14.3 sec | 496 ms | ~2,778% |
| BigQuery | 2,834 ms | 2,769 ms | ~2% |
| Athena | 3,068 ms | 3,087 ms | ~0% |
Cold start analysis based on narrow queries (Q01-Q42). Overall Results include wide scans which increase Athena's median.
DuckDB + R2 cold starts range from 14-20 seconds depending on config. The first query has to fetch Parquet metadata (file footers, schema, row group info) over the network before any real work can happen. Subsequent queries are fast because this metadata is cached.
DuckDB Local has minimal cold start overhead (~5-8%). BigQuery and Athena also have minimal overhead (~2% and ~0% respectively).
Wide Scans Change Everything
We added 15 SELECT * queries to simulate realistic scenarios: data exports, ML feature extraction, backup pipelines.
| Platform | Narrow Queries (42) | With Wide Scans (57) | Change |
|---|---|---|---|
| Athena | $0.0037/query | $0.0064/query | +73% |
| BigQuery | $0.0284/query | $0.0282/query | -1% |
Athena's lower cost on narrow queries comes from column pruning. When you SELECT *, there's nothing to prune. Costs converge toward BigQuery's level.
Workload mix matters. Wide scans eliminate any cost difference between the two platforms.
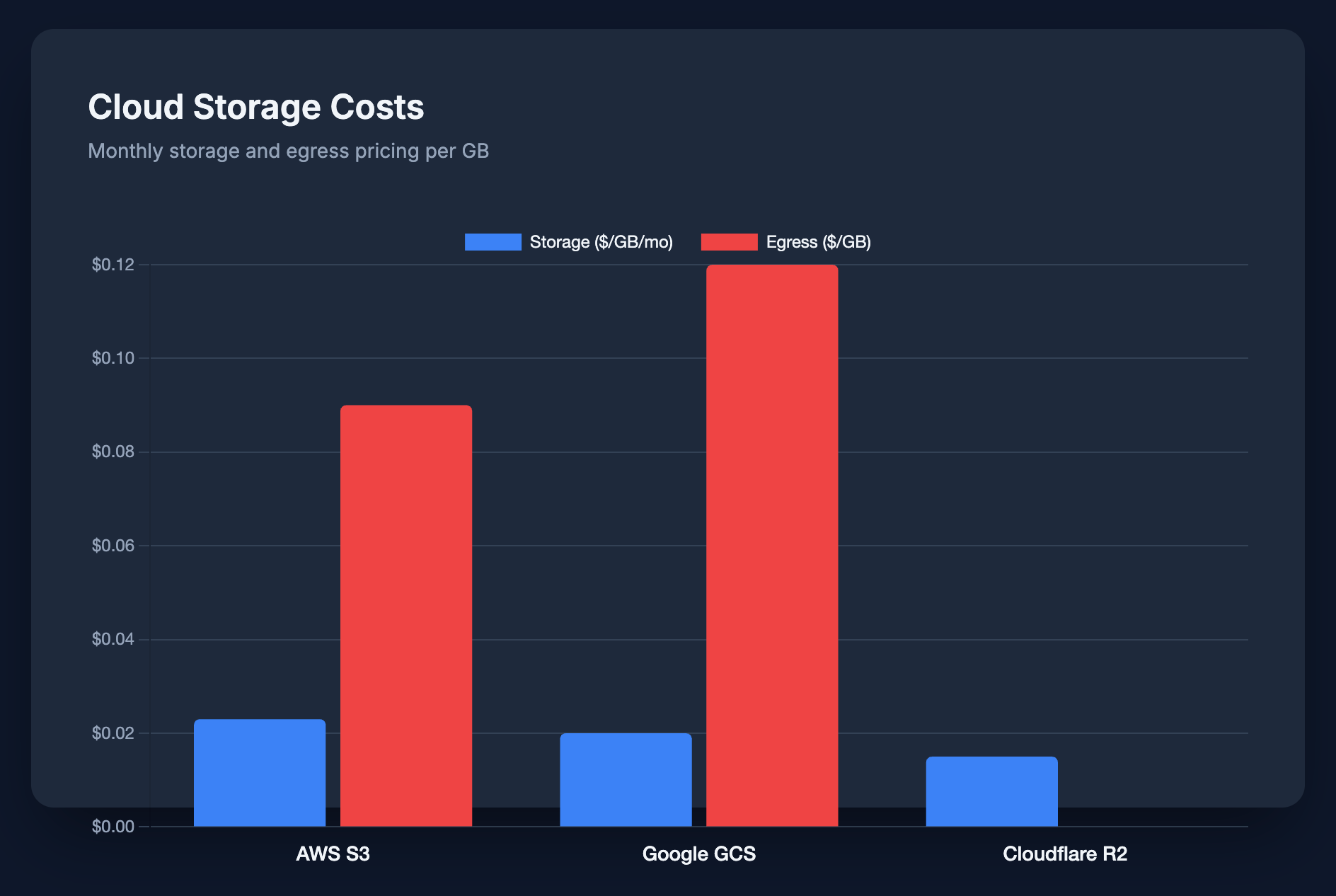
Storage Costs
Query costs get the attention, but storage is a recurring monthly expense:
| Provider | Storage ($/GB/mo) | Egress ($/GB) |
|---|---|---|
| AWS S3 | $0.023 | $0.09 |
| Google GCS | $0.020 | $0.12 |
| Cloudflare R2 | $0.015 | $0.00 |
R2 is 35% cheaper than S3 for storage alone. R2 also has zero egress fees.
For DuckDB + remote storage at scale:
| Storage | 1000 queries/day × 5GB each |
|---|---|
| S3 | $0.09 × 5000 = $450/day = $13,500/month |
| R2 | $0/month |
When We'd Use Each Platform
| Scenario | Our Pick | Why |
|---|---|---|
| Sub-second latency required | DuckDB local | 5-8x faster than cloud |
| Large datasets, good warm performance | DuckDB + R2 | Free egress with R2 |
| GCP ecosystem | BigQuery | Integration convenience |
| Sporadic cold queries | BigQuery | Minimal cold start penalty |
Methodology Notes
- 57 queries total: 42 typical analytics (scans, aggregations, joins, windows) + 15 wide scans
- 4 runs per query: First run = cold, remaining 3 = warm
- DuckDB config: Started at 4 threads/8GB, scaled up to 32 threads/64GB
- Cloud platforms: On-demand pricing, no reserved capacity
- Same data: All platforms queried identical Parquet files
Data Format
- Compression: ZSTD
- Partitioning: None
- Sort order:
(symbol, dateEpoch)for time-series tables
Raw data statistics:
- Total files: 156 Parquet files
- Total size: ~20 GB (ZSTD compressed Parquet)
Tables:
| Table | Files | Size | Sort Order |
|---|---|---|---|
| stock_eod | 78 | 12.2 GB (143-169 MB each) | symbol, dateEpoch |
| financial_ratios | 47 | 3.6 GB (7-147 MB each) | symbol, period, dateEpoch |
| income_statement | 19 | 1.6 GB (19-153 MB each) | symbol, period, dateEpoch |
| balance_sheet | 15 | 1.8 GB (83-151 MB each) | symbol, period, dateEpoch |
| profile | 1 | 50 MB | symbol |
| sp500_constituent | 1 | <1 MB | symbol |
Files organized by table type. No date/symbol partitioning.
Limitations
- No partitioning: The test data wasn't partitioned by date or symbol. Partitioning would likely improve performance for all platforms, especially for time-range queries.
- Single region: All platforms were tested in European regions. Results may vary in other regions.
- ZSTD compression: Results are specific to ZSTD-compressed Parquet. Other compression codecs (Snappy, LZ4) may show different performance characteristics.
- No caching layers: No external caching (Redis, Memcached) was used. Production systems often cache frequent queries.
- DuckDB R2 wide scan data: Medium and large configs were benchmarked for R2 wide scans. The Query Type table shows the large config value (1,850 ms). Small and XL configs weren't included.
Data and Compute Locations
| Platform | Data Location | Compute Location | Co-located? |
|---|---|---|---|
| BigQuery | europe-west1 (Belgium) | europe-west1 | Yes |
| Athena | S3 eu-west-1 (Ireland) | eu-west-1 | Yes |
| DuckDB + R2 | Cloudflare R2 (EU) | Lauterbourg, FR | Network hop |
| DuckDB Local | Local SSD | Lauterbourg, FR | Yes |
Why this matters:
- BigQuery and Athena co-locate data and compute in the same region, minimizing network latency
- DuckDB + R2's cold start penalty is due to Parquet metadata fetching over the network. Co-locating storage and compute would reduce the magnitude but not eliminate the penalty.
- Local DuckDB eliminates network entirely, explaining the 5-8x speed advantage
Why We Used R2
We used Cloudflare R2 for the DuckDB remote storage benchmark:
- Zero egress: Testing data transfer without egress charges
- Cheaper storage: 35% less than S3
- S3-compatible API: Same DuckDB code works with S3 or R2
Raw Data
Full benchmark code and results: GitHub: Insydia-Studio/benchmark-duckdb-athena-bigquery
Run It Yourself
Explore the data behind this analysis on Ceta Research. Query our financial data warehouse with SQL, build custom screens, and run your own backtests across 70,000+ stocks on 20 exchanges.
Questions? Open an issue on GitHub.
Past performance does not guarantee future results. This is educational content, not investment advice.